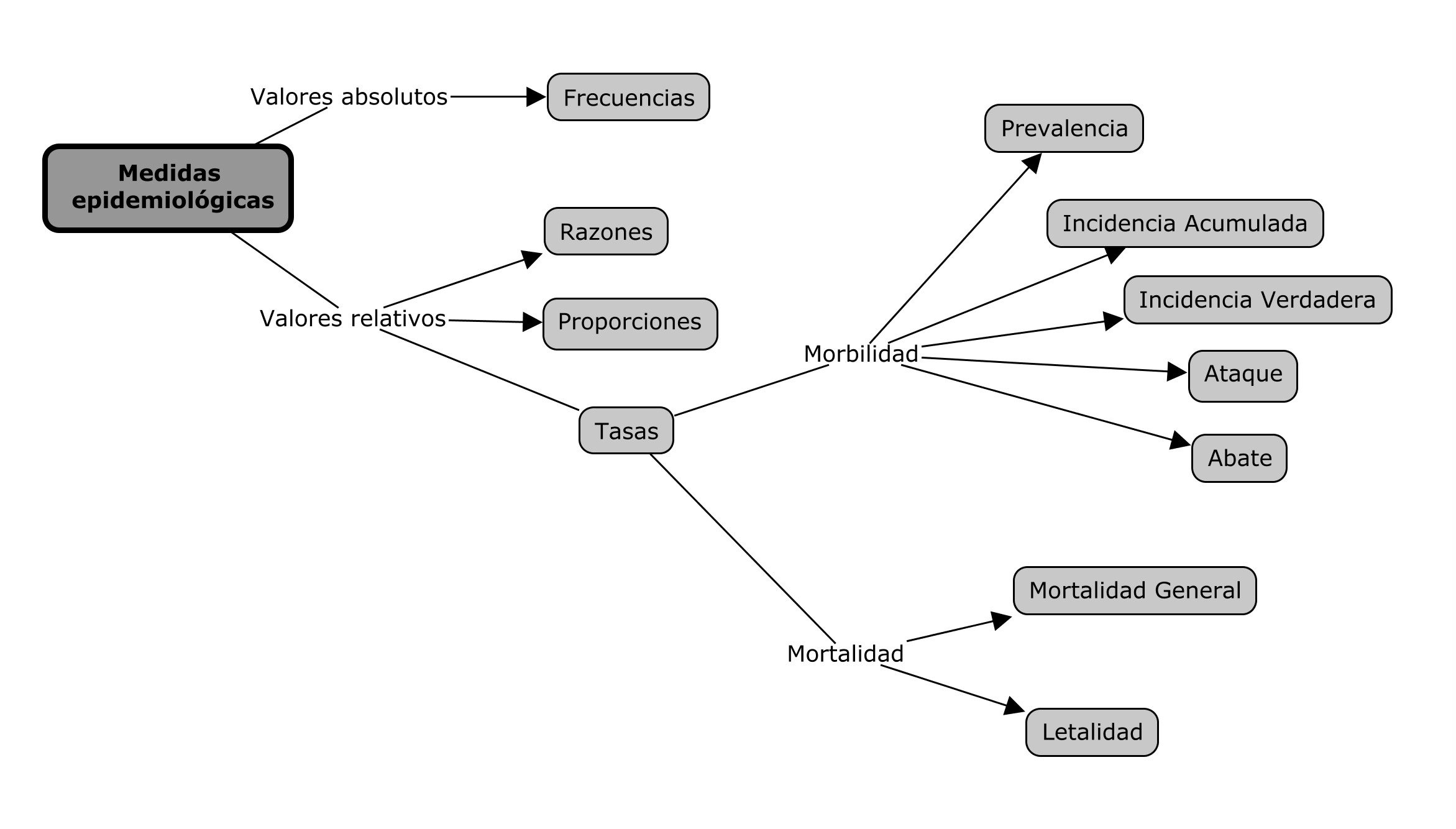
A continuación se muestra una imágen para mapear las razones, proporciones y tasas dentro del contexto de las medidas epidemiológicas.
2.1 Razones
Es el cociente que resulta de dividir dos valores provenientes de conjuntos independientes. (Jaramillo Arango 2010)
# Creación de tabla con n número de machos y n número de hembras rpt <-data.frame(sexo =c(rep("macho", 3),rep("hembra", 7) ))# Impresión de la tabla creadarpt
# Cálculo de la razón de hembras contra machostable(rpt)[1] /table(rpt)[2]
hembra
2.333333
# Cálculo de la razón de machos contra hembrastable(rpt)[2] /table(rpt)[1]
macho
0.4285714
2.2 Proporciones
Implica que en nuestra división el numerador forma parte del denominador. (Jaramillo Arango 2010)
prop.table(table(rpt))
sexo
hembra macho
0.7 0.3
2.3 Tasas
Son formas especiales de proporciones, básicamente están constituidas por un numerador, un denominador y un factor de multiplicación. (Jaramillo Arango 2010)
El factor de multiplicación es \(10^n\), donde n puede tomar diferentes valores que se muestran a continuación:
La morbilidad permite conocer qué tanto se presenta la enfermedad en la población. (Jaramillo Arango 2010)
2.3.1.1 Tasa de Prevalencia (TP)
Indica la cantidad de enfermedad que existe en una población. (Jaramillo Arango 2010)
La Tasa de Prevalencia resulta de dividir el total de casos en una población en un lugar y momento dados dentro del total de la población en ese lugar y momento dados.
Obsérvece como en el formato “tidy” las enfermedades que antes ocupaban 3 columnas ahora ocupan una sola, y se agregó la columna “casos” en la que se colocó el conteo de dichas enfermedades.
Esta estructura de datos facilita hacer cálculos agrupando por enfermedades.
Es importante notar que en este caso es útil ordenar los datos de esta forma dado que todas todos los valores correspondientes a las 3 enfermedades corresponden a frecuencias, es decir conteos; sin embargo, no hubiese sido conveniente la transformación si cada enfermedad hubiese tenido un parámetro distinto, por ejemplo si las enfermedades respiratorias hubiesen tenido como valor un resultado de PCR, las enfermedades digestivas un porcentaje de diarrea, y las enfermedades nerviosas una escala de gravedad. En ese caso, colocar las 3 enfermedades en una sola columna conllevaría incumplir con el precepto de los datos “tidy” de que cada variable debe tener su propia columna y que observación debe tener su propia fila (porque si cada enfermedad tiene distinta escala de medición, se convierte en una variable distinta).
Bien, para calcular la prevalencia anual, agregamos una columna de año, usamos esa nueva variable para agrupar los datos y aplicamos la fórmula que como ya vimos consiste en sumar los casos y dividirlos dentro de la población total, en este caso lo multiplicamos por 1,000; entonces el resultado debe interpretarse como casos por cada 1,000 individuos.
morbilidad_simulada_pivot_datos_agrupados |>ggplot(aes(año, prevalencia, col = enfermedades)) +geom_line()
2.3.1.2 Tasa de Incidencia Acumulada (TIA)
La TIA representa los casos nuevos en una población y en un período de tiempo determinado.
\[\begin{equation}{}
TIA = \frac{cn^{tl}} {N^{tl}}10^n
\end{equation}\]
Donde:
\(cn^{tl}\) = Casos nuevos en una población en un tiempo y lugar y dados.
\(N^{tl}\) = Total de la población en un tiempo y lugar dados
Para calcular la TIA debemos ante todo tener la certeza que los casos son nuevos, por tanto debemos asegurarnos de tener la trazabilidad adecuada. Si estamos evaluando la frecuencia de las enfermedades en una explotación como una granja grande y tan solo por los signos clínicos es muy difícil diferenciar entre casos nuevos y casos viejos, así que casi todas las evaluaciones corresponderán a Prevalencia. Si por el contrario, estamos evaluando la frecuencia de enfermedad mediante análisis de laboratorio, entonces sí podemos asegurarnos de llevar la trazabilidad de los animales muestreados y así poder distinguir entre Prevalencia e Incidencia.
Para la TIA usaremos un ejemplo donde hubo 12 vacas que enfermaron a lo largo del año de una población total de 500 vacas, los datos se muestran en la siguiente tabla
La incidencia permite conocer la probabilidad de ocurrencia de casos nuevos en una población en un tiempo dado, mide la rapidez con la cual se desarrolla una enfermedad, por lo que proporciona la idea más exacta de los nuevos casos, considerando el tiempo a riesgo que tienen cada uno de los individuos para enfermar. (Jaramillo Arango 2010)
\(cn^{tl}\) = Casos nuevos en una población en un tiempo y lugar y dados.
\(ee\) = Suma de períodos de exposición de los animales que enfermaron.
\(es\) = Suma de períodos de exposición de los animales que no enfermaron.
N =500n <-nrow(tabla_TI)meses <-12ee <-sum(tabla_TI$inicio) - nes <- (N-n) * meses TIV <- n / (ee + es)TIV *1000
[1] 2.027369
La Tasa de Incidencia Verdadera es de 2 por cada 1,000 animales, es decir que la probabilidad mensual de adquirir la enfermedad es de 2 vacas por cada 1,000
Jaramillo Arango, Carlos Julio. 2010. Epidemiologia Veterinaria. 1st ed. México: El Manual Moderno.
Wickham, Hadley. 2017. R for Data Science. 1st ed. O´´Reilly.